docker 入门
基础知识
chroot 命令
chroot,即 change root directory (更改 root 目录)。在 linux 系统中,系统默认的目录结构都是以 /,即以根 (root) 开始的。而在使用 chroot 之后,系统的目录结构将以指定的位置作为 / 位置。
为什么要使用 chroot 命令
-
增加了系统的安全性,限制了用户的权力: 在经过 chroot 之后,在新根下将访问不到旧系统的根目录结构和文件,这样就增强了系统的安全性。一般会在用户登录前应用 chroot,把用户的访问能力控制在一定的范围之内。
-
建立一个与原系统隔离的系统目录结构,方便用户的开发: 使用 chroot 后,系统读取的是新根下的目录和文件,这是一个与原系统根下文件不相关的目录结构。在这个新的环境中,可以用来测试软件的静态编译以及一些与系统不相关的独立开发。
-
切换系统的根目录位置,引导 Linux 系统启动以及急救系统等: chroot 的作用就是切换系统的根位置,而这个作用最为明显的是在系统初始引导磁盘的处理过程中使用,从初始 RAM 磁盘 (initrd) 切换系统的根位置并执行真正的 init,本文的最后一个 demo 会详细的介绍这种用法
使用demo
mkdir rootfs #busybox 包含了丰富的工具,我们可以把这些工具放置在一个目录下,然后通过 chroot 构造出一个 mini 系统。简单起见我们直接使用 docker 的 busybox 镜像打包的文件系统。先在当前目录下创建一个目录 rootfs:
$ (docker export $(docker create busybox) | tar -C rootfs -xvf -) #然后把 busybox 镜像中的文件释放到这个目录中:
sudo chroot rootfs /bin/ls #虽然输出结果与刚才执行的 ls rootfs 命令形同,但是这次运行的命令却是 rootfs/bin/ls。
sudo chroot rootfs /bin/pwd #输出 pwd 命令真把 rootfs 目录当根目录了!
Linux namespace 的概念
Linux 内核从版本 2.4.19 开始陆续引入了 namespace 的概念。其目的是将某个特定的全局系统资源 通过抽象方法使得namespace 中的进程看起来拥有它们自己的隔离的全局系统资源实例。Linux 内核中实现了六种 namespace,按照引入的先后顺序,列表如下:

Linux namespace 的概念说简单也简单说复杂也复杂。简单来说,我们只要知道,处于某个 namespace 中的进程,能看到独立的它自己的隔离的某些特定系统资源;复杂来说,可以去看看 Linux 内核中实现 namespace 的原理,网络上也有大量的文档供参考,这里不再赘述。
各个namespace介绍
UTS Namespace
UTS Namespace用于对主机名和域名进行隔离,也就是uname系统调用使用的结构体struct utsname里的nodename和domainname这两个字段,UTS这个名字也是由此而来的。 那么,为什么要使用UTS Namespace做隔离?这是因为主机名可以用来代替IP地址,因此,也就可以使用主机名在网络上访问某台机器了,如果不做隔离,这个机制在容器里就会出问题。
IPC Namespace
IPC是Inter-Process Communication的简写,也就是进程间通信。Linux提供了很多种进程间通信的机制,IPC Namespace针对的是SystemV IPC和Posix消息队列。这些IPC机制都会用到标识符,例如用标识符来区别不同的消息队列,然后两个进程通过标识符找到对应的消息队列进行通信等。 IPC Namespace能做到的事情是,使相同的标识符在两个Namespace中代表不同的消息队列,这样也就使得两个Namespace中的进程不能通过IPC进程通信了。
PID Namespace
PID Namespace用于隔离进程PID号,这样一来,不同的Namespace里的进程PID号就可以是一样的了。
Network Namespace
这个Namespace会对网络相关的系统资源进行隔离,每个Network Namespace都有自己的网络设备、IP地址、路由表、/proc/net目录、端口号等。网络隔离的必要性是很明显的,举一个例子,在没有隔离的情况下,如果两个不同的容器都想运行同一个Web应用,而这个应用又需要使用80端口,那就会有冲突了。
Mount namespace
Mount namespace通过隔离文件系统挂载点对隔离文件系统提供支持,它是历史上第一个Linux namespace,所以它的标识位比较特殊,就是CLONE_NEWNS。隔离后,不同mount namespace中的文件结构发生变化也互不影响。你可以通过/proc/[pid]/mounts查看到所有挂载在当前namespace中的文件系统,还可以通过/proc/[pid]/mountstats看到mount namespace中文件设备的统计信息,包括挂载文件的名字、文件系统类型、挂载位置等等。
进程在创建mount namespace时,会把当前的文件结构复制给新的namespace。新namespace中的所有mount操作都只影响自身的文件系统,而对外界不会产生任何影响。这样做非常严格地实现了隔离,但是某些情况可能并不适用。比如父节点namespace中的进程挂载了一张CD-ROM,这时子节点namespace拷贝的目录结构就无法自动挂载上这张CD-ROM,因为这种操作会影响到父节点的文件系统。
ps: 在mount这块,需要特别注意,挂载的传播性。在实际应用中,很重要。2006 年引入的挂载传播(mount propagation)解决了这个问题,挂载传播定义了挂载对象(mount object)之间的关系,系统用这些关系决定任何挂载对象中的挂载事件如何传播到其他挂载对象。所谓传播事件,是指由一个挂载对象的状态变化导致的其它挂载对象的挂载与解除挂载动作的事件。
User Namespace
User Namespace用来隔离用户和组ID,也就是说一个进程在Namespace里的用户和组ID与它在host里的ID可以不一样,这样说可能读者还不理解有什么实际的用处。User Namespace最有用的地方在于,host的普通用户进程在容器里可以是0号用户,也就是root用户。这样,进程在容器内可以做各种特权操作,但是它的特权被限定在容器内,离开了这个容器它就只有普通用户的权限了。
Linux资源管理之cgroups
引子
cgroups 是Linux内核提供的一种可以限制单个进程或者多个进程所使用资源的机制,可以对 cpu,内存等资源实现精细化的控制,目前越来越火的轻量级容器 Docker 就使用了 cgroups 提供的资源限制能力来完成cpu,内存等部分的资源控制。
另外,开发者也可以使用 cgroups 提供的精细化控制能力,限制某一个或者某一组进程的资源使用。比如在一个既部署了前端 web 服务,也部署了后端计算模块的八核服务器上,可以使用 cgroups 限制 web server 仅可以使用其中的六个核,把剩下的两个核留给后端计算模块。
本文从以下四个方面描述一下 cgroups 的原理及用法:
cgroups 的概念及原理
cgroups 文件系统概念及原理
cgroups 使用方法介绍
cgroups 实践中的例子
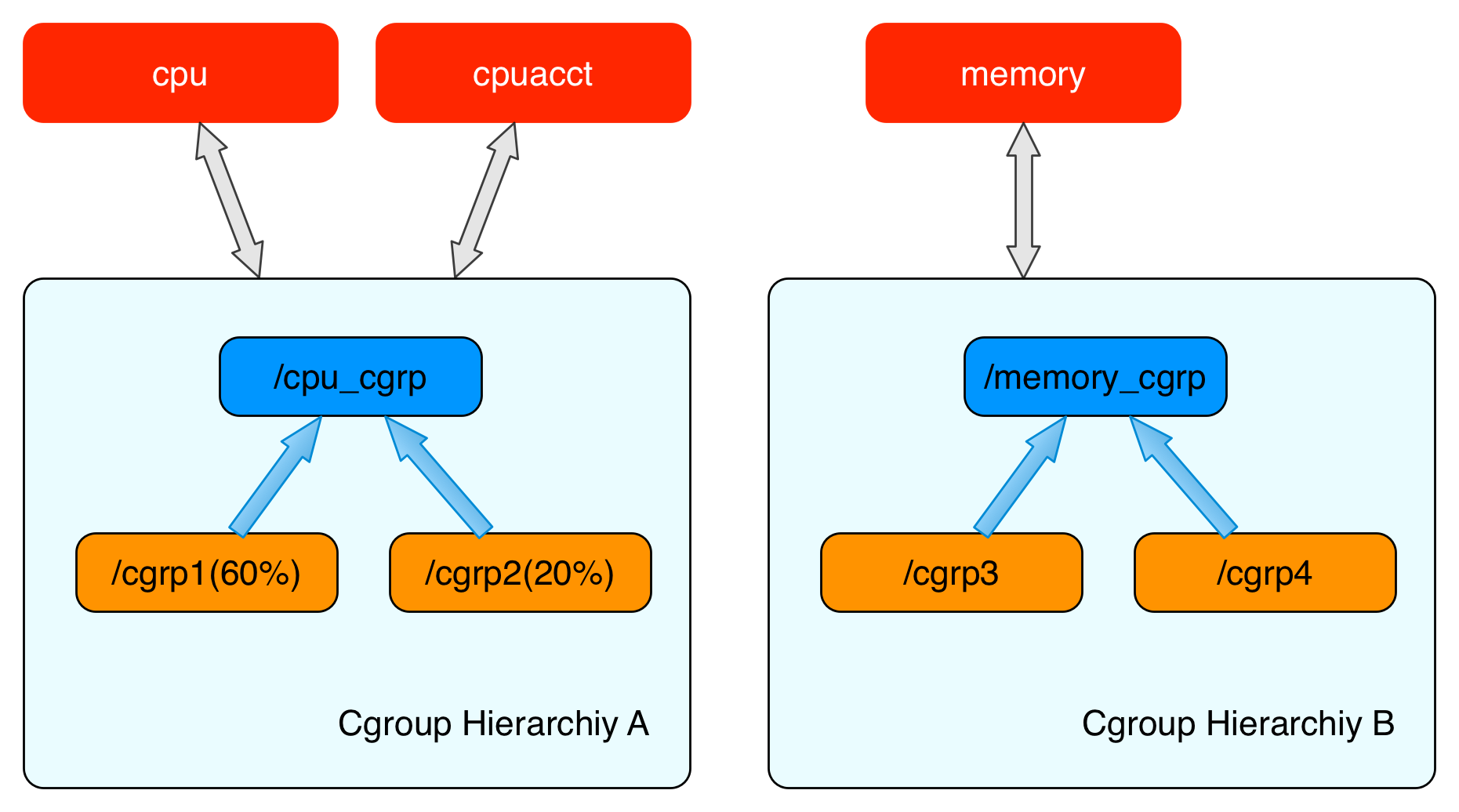
cgroups 的全称是control groups,cgroups为每种可以控制的资源定义了一个子系统。典型的子系统介绍如下:
cpu 子系统,主要限制进程的 cpu 使用率。
cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告。
cpuset 子系统,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
memory 子系统,可以限制进程的 memory 使用量。
blkio 子系统,可以限制进程的块设备 io。
devices 子系统,可以控制进程能够访问某些设备。
net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
freezer 子系统,可以挂起或者恢复 cgroups 中的进程。
ns 子系统,可以使不同 cgroups 下面的进程使用不同的 namespace。
这里面每一个子系统都需要与内核的其他模块配合来完成资源的控制,比如对 cpu 资源的限制是通过进程调度模块根据 cpu 子系统的配置来完成的;对内存资源的限制则是内存模块根据 memory 子系统的配置来完成的,而对网络数据包的控制则需要 Traffic Control 子系统来配合完成。本文不会讨论内核是如何使用每一个子系统来实现资源的限制,而是重点放在内核是如何把 cgroups 对资源进行限制的配置有效的组织起来的,和内核如何把cgroups 配置和进程进行关联的,以及内核是如何通过 cgroups 文件系统把cgroups的功能暴露给用户态的。
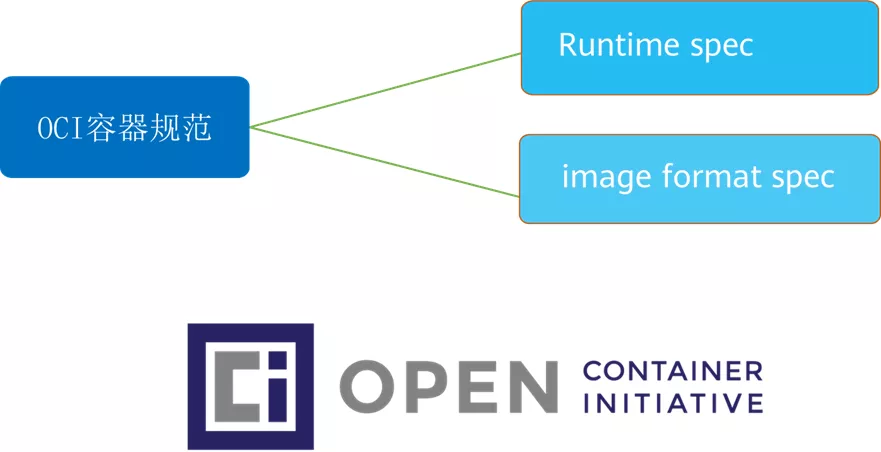
RunC 是什么?
RunC 是一个轻量级的工具,它是用来运行容器的,只用来做这一件事,并且这一件事要做好。我们可以认为它就是个命令行小工具,可以不用通过 docker 引擎,直接运行容器。事实上,runC 是标准化的产物,它根据 OCI 标准来创建和运行容器。而 OCI(Open Container Initiative)组织,旨在围绕容器格式和运行时制定一个开放的工业化标准。
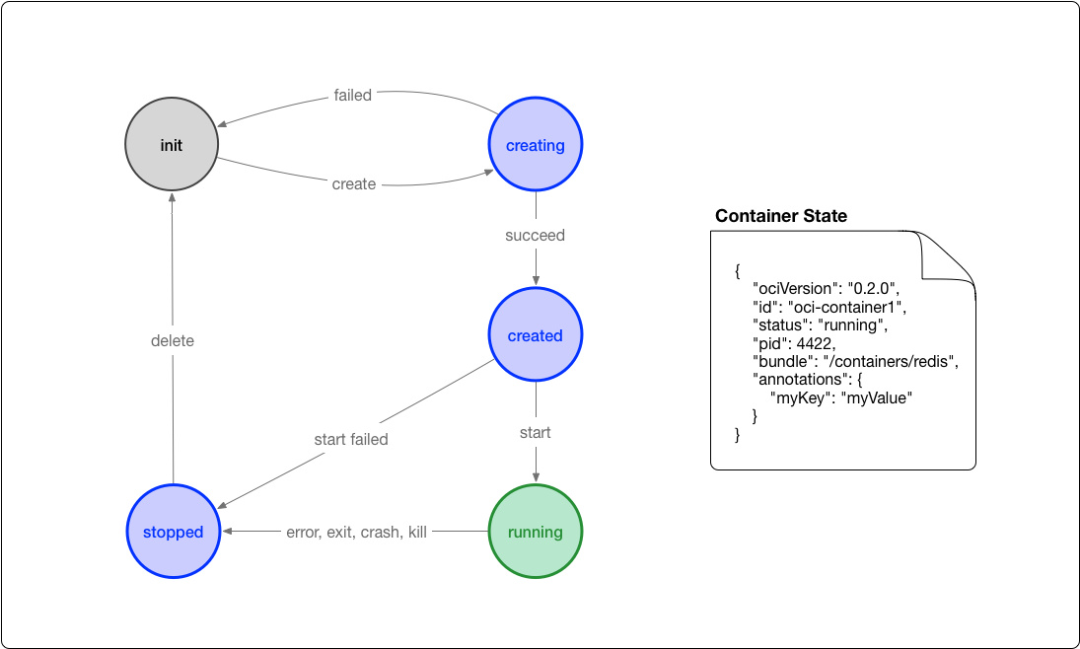
init 状态:这个是我自己添加的状态,并不在标准中,表示没有容器存在的初始状态
creating:使用 create 命令创建容器,这个过程称为创建中
created:容器创建出来,但是还没有运行,表示镜像和配置没有错误,容器能够运行在当前平台
running:容器的运行状态,里面的进程处于 up 状态,正在执行用户设定的任务
stopped:容器运行完成,或者运行出错,或者 stop 命令之后,容器处于暂停状态。这个状态,容器还有很多信息保存在平台中,并没有完全被删除
RunC 是从 Docker 的 libcontainer 中迁移而来的,实现了容器启停、资源隔离等功能。Docker将RunC捐赠给 OCI 作为OCI 容器运行时标准的参考实现。Docker 默认提供了 docker-runc 实现。事实上,通过 containerd 的封装,可以在 Docker Daemon 启动的时候指定 RunC的实现。最初,人们对 Docker 对 OCI 的贡献感到困惑。他们贡献的是一种“运行”容器的标准方式,仅此而已。它们不包括镜像格式或注册表推/拉格式。当你运行一个 Docker 容器时,这些是 Docker 实际经历的步骤:
下载镜像 将镜像文件解开为bundle文件,将一个文件系统拆分成多层 从bundle文件运行容器
Docker标准化的仅仅是第三步。在此之前,每个人都认为容器运行时支持Docker支持的所有功能。最终,Docker方面澄清:原始OCI规范指出,只有“运行容器”的部分组成了runtime。这种“概念失联”一直持续到今天,并使“容器运行时”成为一个令人困惑的话题。希望我能证明双方都不是完全错误的,并且在本文中将广泛使用该术语。RunC 就可以按照这个 OCI 文档来创建一个符合规范的容器,既然是标准肯定就有其他 OCI 实现,比如 Kata、gVisor 这些容器运行时都是符合 OCI 标准的。
UnionFS
1)什么是UnionFS
联合文件系统(Union File System):2004年由纽约州立大学石溪分校开发,它可以把多个目录(也叫分支)内容联合挂载到同一个目录下,而目录的物理位置是分开的。UnionFS允许只读和可读写目录并存,就是说可同时删除和增加内容。UnionFS应用的地方很多,比如在多个磁盘分区上合并不同文件系统的主目录,或把几张CD光盘合并成一个统一的光盘目录(归档)。另外,具有写时复制(copy-on-write)功能UnionFS可以把只读和可读写文件系统合并在一起,虚拟上允许只读文件系统的修改可以保存到可写文件系统当中。 2)docker的镜像rootfs,和layer的设计
任何程序运行时都会有依赖,无论是开发语言层的依赖库,还是各种系统lib、操作系统等,不同的系统上这些库可能是不一样的,或者有缺失的。为了让容器运行时一致,docker将依赖的操作系统、各种lib依赖整合打包在一起(即镜像),然后容器启动时,作为它的根目录(根文件系统rootfs),使得容器进程的各种依赖调用都在这个根目录里,这样就做到了环境的一致性。
不过,这时你可能已经发现了另一个问题:难道每开发一个应用,都要重复制作一次rootfs吗(那每次pull/push一个系统岂不疯掉)?
比如,我现在用Debian操作系统的ISO做了一个rootfs,然后又在里面安装了Golang环境,用来部署我的应用A。那么,我的另一个同事在发布他的Golang应用B时,希望能够直接使用我安装过Golang环境的rootfs,而不是重复这个流程,那么本文的主角UnionFS就派上用场了。
Docker镜像的设计中,引入了层(layer)的概念,也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量rootfs(一个目录),这样应用A和应用B所在的容器共同引用相同的Debian操作系统层、Golang环境层(作为只读层),而各自有各自应用程序层,和可写层。启动容器的时候通过UnionFS把相关的层挂载到一个目录,作为容器的根文件系统。
需要注意的是,rootfs只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。这就意味着,如果你的应用程序需要配置内核参数、加载额外的内核模块,以及跟内核进行直接的交互,你就需要注意了:这些操作和依赖的对象,都是宿主机操作系统的内核,它对于该机器上的所有容器来说是一个“全局变量”,牵一发而动全身。 3)各Linux版本的UnionFS不同
由于各种原因(有兴趣的可自行谷歌),Linux各发行版实现的UnionFS各不相同,所以Docker在不同linux发行版中使用的也不同。你可以通过docker info来查看docker使用的是哪种,比如:
centos, docker18.03.1-ce: Storage Driver: overlay2 debain, docker17.03.2-ce: Storage Driver: aufs
docker 简介
Docker 是一个开源的应用容器引擎,基于 go 语言开发,可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 服务器。容器是一个沙箱机制,相互之间不会有影响(类似于我们手机上运行的 app),并且容器开销是很低的。
用官方的话来说,Docker 受欢迎,是因为以下几个特点:
灵活性:即使是最复杂的应用也可以集装箱化
轻量级:容器利用并共享主机内核
可互换:您可以即时部署更新和升级
便携式:您可以在本地构建,部署到云,并在任何地方运行
可扩展:您可以增加并自动分发容器副本
可堆叠:您可以垂直和即时堆叠服务
Docker 几个重要概念
在了解了 Docker 是什么之后,我们需要先了解下 Docker 中最重要的3个概念:镜像、容器和仓库。
镜像 是一个只读模板,带有创建 Docker 容器的说明,一般来说的,镜像会基于另外的一些基础镜像并加上一些额外的自定义功能来组成。比如,你可以构建一个基于 Centos 的镜像,然后在这个基础镜像上面安装一个 Nginx 服务器,这样就可以构成一个属于我们自己的镜像了。
容器 是一个镜像的可运行的实例,可以使用 Docker REST API 或者 CLI 命令行工具来操作容器,容器的本质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的命名空间。因此容器可以拥有自己的 root 文件系统、自己的网络配置、自己的进程空间,甚至自己的用户 ID 空间。容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下操作一样。这种特性使得容器封装的应用比直接在宿主运行更加安全。
registry 是用来存储 Docker 镜像的仓库,Docker Hub 是 Docker 官方提供的一个公共仓库,而且 Docker 默认也是从 Docker Hub 上查找镜像的,当然你也可以很方便的运行一个私有仓库,当我们使用 docker pull 或者 docker run 命令时,就会从我们配置的 Docker 镜像仓库中去拉取镜像,使用 docker push 命令时,会将我们构建的镜像推送到对应的镜像仓库中,registry 可以理解为用于镜像的 github 这样的托管服务。
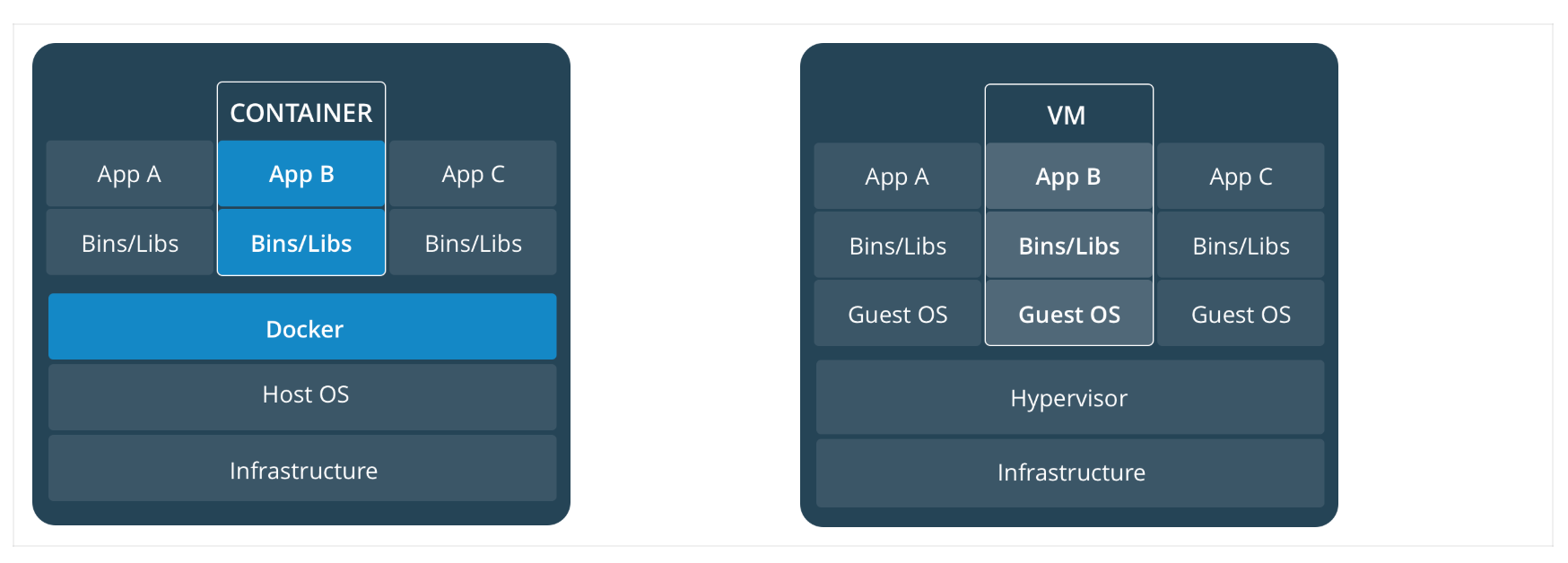
容器和虚拟机区别
上面我们说到了容器是在 Linux 上本机运行,并与其他容器共享主机的内核,它运行一个独立的进程,不占用其他任何可执行文件的内存,非常轻量。
而虚拟机运行的是一个完整的操作系统,通过虚拟机管理程序对主机资源进行虚拟访问,相比之下需要的资源需要更多,但是非常安全,因为是独立的操作系统,独立的内核。
Docker 架构
Docker 使用 C/S (客户端/服务器)体系的架构,Docker 客户端与 Docker 守护进程(Dockerd)通信,Docker 守护进程负责构建,运行和分发 Docker 容器。Docker 客户端和守护进程可以在同一个系统上运行,也可以将 Docker 客户端连接到远程 Docker 守护进程。Docker 客户端和守护进程使用 REST API 通过 UNIX 套接字或网络接口进行通信。
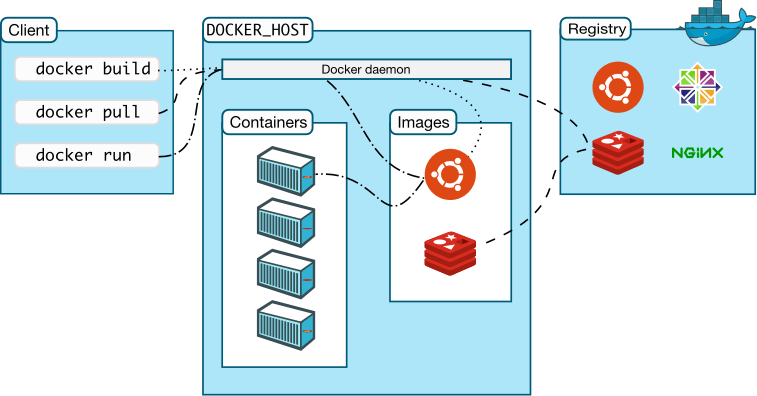
Docker 网络
Bridge 模式
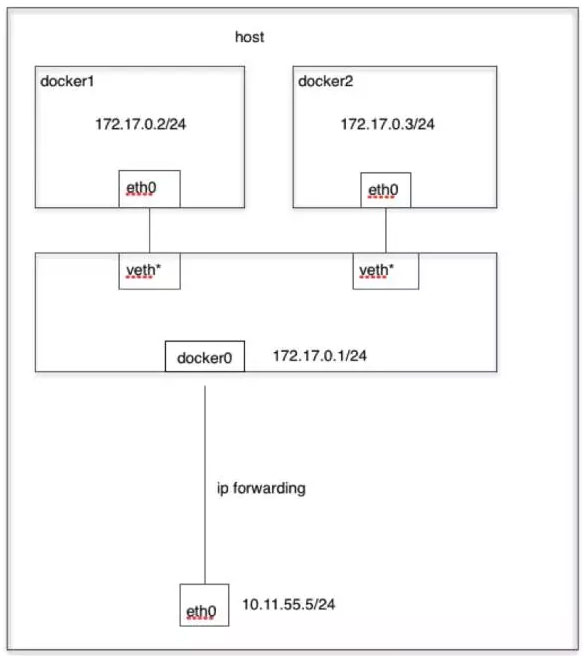
当 Docker 进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的 Docker 容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。从 docker0 子网中分配一个 IP 给容器使用,并设置 docker0 的 IP 地址为容器的默认网关。在主机上创建一对虚拟网卡veth pair设备,Docker 将 veth pair 设备的一端放在新创建的容器中,并命名为 eth0(容器的网卡),另一端放在主机中,以vethxxx这样类似的名字命名,并将这个网络设备加入到 docker0 网桥中。
bridge 模式是 docker 的默认网络模式,使用docker run -p时,实际上是通过 iptables 做了DNAT规则,实现端口转发功能。可以使用iptables -t nat -vnL查看。bridge模式如下图所示
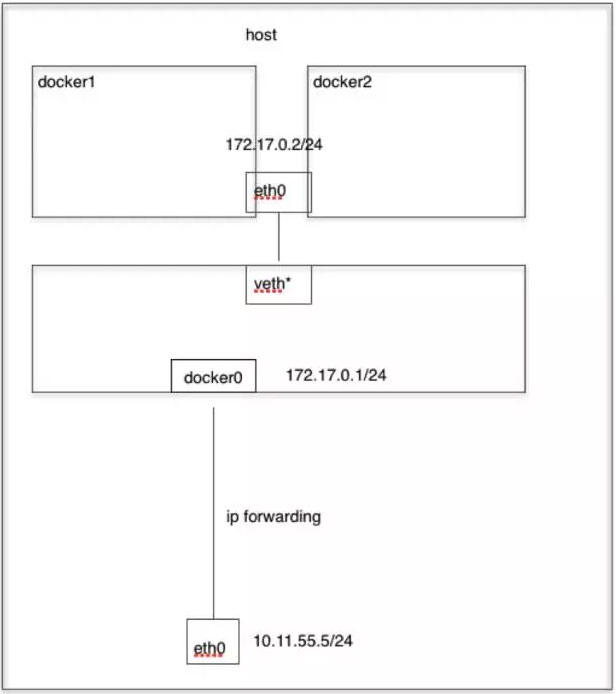
自定义网络
这个时候我们可以通过自定义网络的方式来实现互联互通,首先创建一个自定义的网络:
$ docker network create -d bridge my-net
然后我们使用自定义的网络运行一个容器:
$ docker run -it --rm --name busybox1 --network my-net busybox sh
打开终端再运行一个容器:
$ docker run -it --rm --name busybox2 --network my-net busybox sh
然后我们通过 ping 来证明 busybox1 容器和 busybox2 容器建立了互联关系。 在 busybox1 容器输入以下命令:
/ # ping busybox2
PING busybox2 (172.19.0.3): 56 data bytes
64 bytes from 172.19.0.3: seq=0 ttl=64 time=0.072 ms
64 bytes from 172.19.0.3: seq=1 ttl=64 time=0.118 ms
用 ping 来测试连接 busybox2 容器,它会解析成 172.19.0.3。 同理在 busybox2 容器执行 ping busybox1,也会成功连接到:
/ # ping busybox1
PING busybox1 (172.19.0.2): 56 data bytes
64 bytes from 172.19.0.2: seq=0 ttl=64 time=0.064 ms
64 bytes from 172.19.0.2: seq=1 ttl=64 time=0.143 ms
这样,busybox1 容器和 busybox2 容器建立了互联关系,如果你有多个容器之间需要互相连接,推荐使用后面的 Docker Compose。
Host 模式
如果启动容器的时候使用 host 模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个 Network Namespace。容器将不会虚拟出自己的网卡,配置自己的 IP 等,而是使用宿主机的 IP 和端口。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。 Host模式如下图所示:

使用 host 模式也很简单,只需要在运行容器的时候指定 –net=host 即可。
Container 模式
这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。 Container 模式如下图所示
在运行容器的时候指定 –net=container:目标容器名 即可。实际上我们后面要学习的 Kubernetes 里面的 Pod 中容器之间就是通过 Container 模式链接到 pause 容器上面的,所以容器直接可以通过 localhost 来进行访问
None 模式
使用 none模式,Docker 容器拥有自己的 Network Namespace,但是并不为Docker 容器进行任何网络配置。也就是说这个 Docker 容器没有网卡、IP、路由等信息。需要我们自己为 Docker 容器添加网卡、配置 IP 等。 None模式示意图如下所示:

参考文献
https://www.cnblogs.com/sparkdev/p/8556075.html
https://www.qikqiak.com/k8strain2/docker/overview/
https://www.cnblogs.com/sparkdev/p/9032209.html
https://www.51cto.com/article/687502.html
https://segmentfault.com/a/1190000016357628
https://tech.meituan.com/2015/03/31/cgroups.html
https://www.jianshu.com/p/3ba255463047