Virtual DOM 算法简单介绍
为什么要有虚拟DOM
DOM是很慢的。如果我们把一个简单的div元素的属性都打印出来,你会发现他包含很多默认属性和内置属性。真正的 DOM 元素非常庞大,这是因为标准就是这么设计的。而且操作它们的时候你要小心翼翼,轻微的触碰可能就会导致页面重排,这可是杀死性能的罪魁祸首。
虚拟DOM的组成
相对于 DOM 对象,原生的 JavaScript 对象处理起来更快,而且更简单。DOM 树上的结构、属性信息我们都可以很容易地用 JavaScript 对象表示出来:
var root = {
tagName: 'ul', // 节点标签名
props: { // DOM的属性,用一个对象存储键值对
id: 'list'
},
children: [ // 该节点的子节点
{tagName: 'li', props: {class: 'item'}, children: ["Item 1"]},
{tagName: 'li', props: {class: 'item'}, children: ["Item 2"]},
{tagName: 'li', props: {class: 'item'}, children: ["Item 3"]},
]
}
上面对应的HTML写法是:
<ul id='list'>
<li class='item'>Item 1</li>
<li class='item'>Item 2</li>
<li class='item'>Item 3</li>
</ul
DOM 树的信息都可以用 JavaScript 对象来表示,反过来,你就可以根据这个用 JavaScript 对象表示的树结构来构建一棵真正的DOM树。 Virtual DOM 本质上就是在 JS 和 DOM 之间做了一个缓存。我们经常遇到一个问题就是磁盘IO操作非常耗时间,所以我们经常使用缓冲区来提高性能,里面的原理就是通过缓存,来减少读写的次数。通过虚拟DOM可以优化性能也是这个道理,因为原生DOM比js对象要重很多。但本质上虚拟DOM还是操作DOM就像IO操作本质上还是磁盘操作没有变。
用JS对象模拟DOM树
function h (tagName, props, children) {
this.tagName = tagName
this.props = props
this.children = children
}
module.exports = function (tagName, props, children) {
return new h(tagName, props, children)
}
例如上面的 DOM 结构就可以简单的表示:
var el = require('./h')
var ul = el('ul', {id: 'list'}, [
el('li', {class: 'item'}, ['Item 1']),
el('li', {class: 'item'}, ['Item 2']),
el('li', {class: 'item'}, ['Item 3'])
])
render方法会根据tagName构建一个真正的DOM节点,然后设置这个节点的属性,最后递归地把自己的子节点也构建起来。所以只需要:
h.prototype.render = function () {
var el = document.createElement(this.tagName) // 根据tagName构建
var props = this.props
for (var propName in props) { // 设置节点的DOM属性
var propValue = props[propName]
el.setAttribute(propName, propValue)
}
var children = this.children || []
children.forEach(function (child) {
var childEl = (child instanceof Element)
? child.render() // 如果子节点也是虚拟DOM,递归构建DOM节点
: document.createTextNode(child) // 如果字符串,只构建文本节点
el.appendChild(childEl)
})
return el
}
var ulRoot = ul.render()
document.body.appendChild(ulRoot)
上面的ulRoot是真正的DOM节点,把它塞入文档中,这样body里面就有了真正的ul的DOM结构:
<ul id='list'>
<li class='item'>Item 1</li>
<li class='item'>Item 2</li>
<li class='item'>Item 3</li>
</ul>
比较两棵虚拟DOM树的差异
正如你所预料的,比较两棵DOM树的差异是 Virtual DOM 算法最核心的部分,这也是所谓的 Virtual DOM 的 diff 算法。两个树的完全的 diff 算法是一个非常复杂的问题。
在实际的代码中,会对新旧两棵树进行一个深度优先的遍历,给每个节点一个索引:
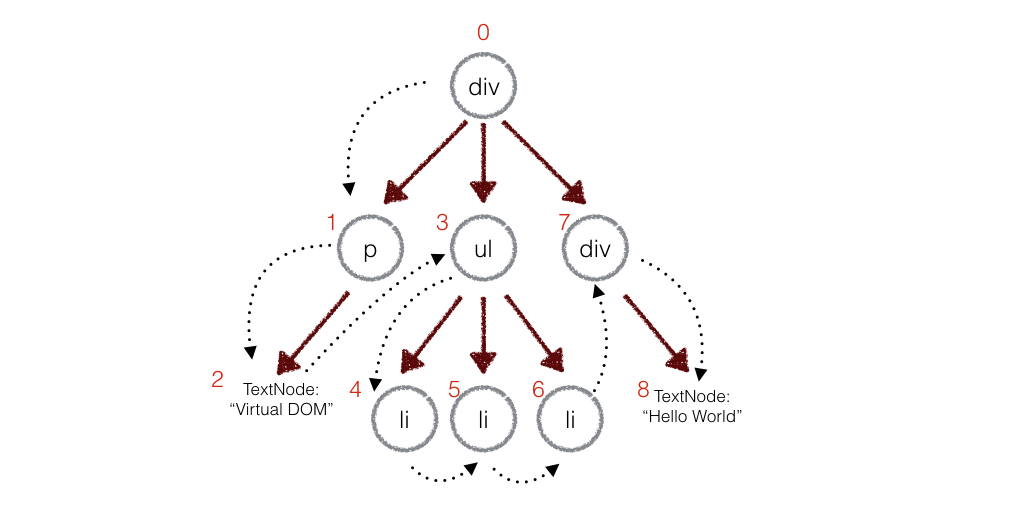
在深度优先遍历的时候,每遍历到一个节点就把该节点和新的的树进行对比。如果有差异的话就记录到一个对象里面。
// diff 函数,对比两棵树
function diff (oldTree, newTree) {
var index = 0 // 当前节点的标志
var patches = {} // 用来记录每个节点差异的对象
dfsWalk(oldTree, newTree, index, patches)
return patches
}
// 对两棵树进行深度优先遍历
function dfsWalk (oldNode, newNode, index, patches) {
// 对比oldNode和newNode的不同,记录下来
patches[index] = [...]
diffChildren(oldNode.children, newNode.children, index, patches)
}
// 遍历子节点
function diffChildren (oldChildren, newChildren, index, patches) {
var leftNode = null
var currentNodeIndex = index //节点的索引
oldChildren.forEach(function (child, i) {
var newChild = newChildren[i]
currentNodeIndex = (leftNode && leftNode.count) // 计算节点的标识
? currentNodeIndex + leftNode.count + 1
: currentNodeIndex + 1
dfsWalk(child, newChild, currentNodeIndex, patches) // 深度遍历子节点
leftNode = child
})
}
还有一个问题就是dom更新会有多种不同的情况,例如替换,新增,修改属性,文本修改等,所以我们还需要标记一下变更类型。
- 替换掉原来的节点,例如把上面的ul换成了ol
- 移动、删除、新增子节点,例如上面div的子节点,把p和ul顺序互换
- 修改了节点的属性
- 对于文本节点,文本内容可能会改变。例如修改上面的文本节点2内容为hello wike。
我们定义了几种差异类型:
var REPLACE = 0
var REORDER = 1
var PROPS = 2
var TEXT = 3
对于节点替换,很简单。判断新旧节点的tagName和是不是一样的,如果不一样的说明需要替换掉。如ul换成ol,就记录下:
patches[0] = [{
type: REPALCE,
node: newNode // el('ol', props, children)
}]
如果给div新增了属性id为container,就记录下:
patches[0] = [{
type: REPALCE,
node: newNode // el('section', props, children)
}, {
type: PROPS,
props: {
id: "container"
}
}]
如果是文本节点,如上面的文本节点2,就记录下:
patches[2] = [{
type: TEXT,
content: "hello wike"
}
具体的diff算法其实很复杂,需要考虑的东西非常多,而且很多性能优化,我觉得如果不是搞底层架构的,没必要去深究具体的实现(Levenshtein Distance,动态规划等),只需要了解其中的概念,和会使用即可。
把差异应用到真正的DOM树上
因为步骤一所构建的 JavaScript 对象树和render出来真正的DOM树的信息、结构是一样的。所以我们可以对那棵DOM树也进行深度优先的遍历,遍历的时候从步骤二生成的patches对象中找出当前遍历的节点差异,然后进行 DOM 操作。
function patch (node, patches) {
var walker = {index: 0}
dfsWalk(node, walker, patches)
}
function dfsWalk (node, walker, patches) {
var currentPatches = patches[walker.index] // 从patches拿出当前节点的差异
var len = node.childNodes
? node.childNodes.length
: 0
for (var i = 0; i < len; i++) { // 深度遍历子节点
var child = node.childNodes[i]
walker.index++
dfsWalk(child, walker, patches)
}
if (currentPatches) {
applyPatches(node, currentPatches) // 对当前节点进行DOM操作
}
}
function applyPatches (node, currentPatches) {
currentPatches.forEach(function (currentPatch) {
switch (currentPatch.type) {
case REPLACE:
node.parentNode.replaceChild(currentPatch.node.render(), node)
break
case REORDER:
reorderChildren(node, currentPatch.moves)
break
case PROPS:
setProps(node, currentPatch.props)
break
case TEXT:
node.textContent = currentPatch.content
break
default:
throw new Error('Unknown patch type ' + currentPatch.type)
}
})
}
Virtual DOM 算法主要是实现上面三个步骤,h(虚拟DOM转DOM),dif(对比差异),patch(实现更新)