bufio的使用
为什么要使用bufio
bufio 是通过缓冲来提高效率。
io操作本身的效率并不低,低的是频繁的访问本地磁盘的文件。所以bufio就提供了缓冲区(分配一块内存), 读和写都先在缓冲区中,最后再读写文件,来降低访问本地磁盘的次数,从而提高效率。
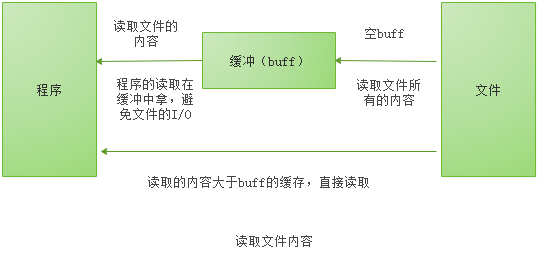
简单的说就是,把文件读取进缓冲(内存)之后再读取的时候就可以避免文件系统的io 从而提高速度。 同理,在进行写操作时,先把文件写入缓冲(内存),然后由缓冲写入文件系统。看完以上解释有人可能会表示困惑了, 直接把 内容->文件 和 内容->缓冲->文件相比, 缓冲区好像没有起到作用嘛。其实缓冲区的设计是为了存储多次的写入, 最后一口气把缓冲区内容写入文件。
什么时候需要使用bufio
当读取的文件比较大时,一次性全部读取文件内容会导致内存占用太多,或者需要多次读取,和多次写入。可以通过bufio来优化程序性能。
假设一个场景 你需要读取 10G的日志文件 ,一次性 copy 会导致内存占用太多,如果直接使用原始的read接口需要自己写很多代码才能实现按行读取,这个时候bufio可以帮助你减少代码量。
再假设一个场景 你需要把mysql数据转换为execl,数据量非常大,你一次性只能取10w条,可能写入操作需要几万次,这个时候bufio可以帮你提高效率。
介绍常用读取操作
func NewReaderSize
func NewReaderSize(rd io.Reader, size int) *Reader
一般只需要把打开的文件句柄传给 NewReaderSize,size可以根据你机器内存,读取对象,系统负载来决定
func NewReader
func NewReader(rd io.Reader) *Reader
一般只需要把打开的文件句柄传给 NewReader,其实NewReader底层调用的是NewReaderSize
常用的方法
func (*Reader) ReadBytes
func (b *Reader) ReadBytes(delim byte) (line []byte, err error)
ReadBytes读取直到第一次遇到delim字节,返回一个包含已读取的数据和delim字节的切片。 如果ReadBytes方法在读取到delim之前遇到了错误,它会返回在错误之前读取的数据以及该错误(一般是io.EOF)。 当且仅当ReadBytes方法返回的切片不以delim结尾时,会返回一个非nil的错误。
func (*Reader) ReadString
func (b *Reader) ReadString(delim byte) (line string, err error)
ReadString读取直到第一次遇到delim字节,返回一个包含已读取的数据和delim字节的字符串。 如果ReadString方法在读取到delim之前遇到了错误,它会返回在错误之前读取的数据以及该错误(一般是io.EOF)。 当且仅当ReadString方法返回的切片不以delim结尾时,会返回一个非nil的错误。
以上2个操作是平时经常使用的唯一的区别只是返回值一个是字节数组一个是字符串,根据你的程序自由选择,如果想按行读取只需要 delim 参数 赋值为 \n
func NewScanner
func NewScanner(r io.Reader) *Scanner
NewScanner创建并返回一个从r读取数据的Scanner,默认的分割函数是ScanLines。也就是按行取
这个功能和上面的读取操作最大的区别是,可以指定特定的分割条件,再特殊需求的情况下可以使用。
func (*Scanner) Scan
func (s *Scanner) Scan() bool
Scan方法获取当前位置的token(该token可以通过Bytes或Text方法获得),并让Scanner的扫描位置移动到下一个token。 当扫描因为抵达输入流结尾或者遇到错误而停止时,本方法会返回false。 在Scan方法返回false后,Err方法将返回扫描时遇到的任何错误;除非是io.EOF,此时Err会返回nil。
scanner := bufio.NewScanner(os.Stdin)
for scanner.Scan() {
fmt.Println(scanner.Text()) // 默认按行取,这个时候打印一行
}
if err := scanner.Err(); err != nil {
fmt.Fprintln(os.Stderr, "reading standard input:", err)
}
func (*Scanner) Bytes
func (s *Scanner) Bytes() []byte
Bytes方法返回最近一次Scan调用生成的token。底层数组指向的数据可能会被下一次Scan的调用重写。
func (*Scanner) Text
func (s *Scanner) Text() string
Text方法返回最近一次Scan调用生成的token,会申请创建一个字符串保存token并返回该字符串。
高级功能
func (*Scanner) Split
func (s *Scanner) Split(split SplitFunc)
Split设置该Scanner的分割函数。本方法必须在Scan之前调用。指定特殊的分割规则
默认的规则有 bufio.ScanWords 按单词 bufio.ScanLines 按行(默认)
自定义 SplitFunc
SplitFunc类型代表用于对输出作词法分析的分割函数。
参数data是尚未处理的数据的一个开始部分的切片, 参数atEOF表示是否Reader接口不能提供更多的数据。 返回值是解析位置前进的字节数,将要返回给调用者的token切片,以及可能遇到的错误。 如果数据不足以(保证)生成一个完整的token,例如需要一整行数据但data里没有换行符, SplitFunc可以返回(0, nil, nil)来告诉Scanner读取更多的数据写入切片然后用从同一位置起始、 长度更长的切片再试一次(调用SplitFunc类型函数)。
如果返回值err非nil,扫描将终止并将该错误返回给Scanner的调用者。
除非atEOF为真,永远不会使用空切片data调用SplitFunc类型函数。 然而,如果atEOF为真,data却可能是非空的、且包含着未处理的文本。
bufio.ScanLines 解析
func ScanLines(data []byte, atEOF bool) (advance int, token []byte, err error) {
// 表示我们已经扫描到结尾了
if atEOF && len(data) == 0 {
return 0, nil, nil
}
// 找到\n的位置
if i := bytes.IndexByte(data, '\n'); i >= 0 { //这里可以根据你自己需要修改
// 把下次开始读取的位置向前移动i + 1位
return i + 1, dropCR(data[0:i]), nil
}
// 这里处理的reader内容全部读取完了,但是内容不为空,所以需要把剩余的数据返回
if atEOF {
return len(data), dropCR(data), nil
}
// 表示现在不能分割,向Reader请求更多的数据
return 0, nil, nil
}
介绍常用写入操作
func NewWriterSize
func NewWriterSize(w io.Writer, size int) *Writer
NewWriterSize创建一个具有最少有size尺寸的缓冲、写入w的Writer。如果参数w已经是一个具有足够大缓冲的Writer类型值,会返回w。
func (*Writer) Write
func (b *Writer) Write(p []byte) (nn int, err error)
Write将p的内容写入缓冲。返回写入的字节数。如果返回值nn < len(p),还会返回一个错误说明原因。
func (*Writer) WriteString
func (b *Writer) WriteString(s string) (int, error)
WriteString写入一个字符串。返回写入的字节数。如果返回值nn < len(s),还会返回一个错误说明原因。
func (*Writer) Flush
func (b *Writer) Flush() error
Flush方法将缓冲中的数据写入下层的io.Writer接口。这个方法很关键,一定要在程序结束之前调用,把内存数据刷盘。
说明
写操作和读操作比简单了很多,只需要根据系统配置设置好缓存大小,和结束时主动调用Flush操作即可